【新智元导读】RAG不存在了?20多人初创公司Magic开发的代码语言模型LTM-2-mini,上下文窗口已经达到了1亿token,相当于一千万行代码。AI模型的运作方式,从此可能从根本上改变!如今,团队已获4.65亿美元融资。
就在刚刚,AI上下文处理的新纪录被打破了!
Magic开发了一个专门针对代码的语言模型——LTM-2-mini。

它的上下文窗口,包含1亿个token,相当于1000万行代码,或750部小说。
这远远超出了以前的限制,AI模型的运作方式,从此可能从根本上改变!
从此,我们再也不需要RAG了?
而且,LTM-2-mini采用了序列维度算法,这种计算效率要比Llama 3.1 405B的注意力机制高出约1000倍。

这种能力,极大地扩展了模型在实际应用中的适用范围。在软件开发中,模型可以利用整个代码库、相关文档和库,来生成更高质量的代码了!
在这个过程中,团队还设计了一个新的评估上下文长度和可靠性的体系HashHop,取代了「大海捞针」。
哈希是随机的,因此是不可压缩的,这就要求模型能够在任何时候,存储和检索给定上下文大小的最大可能信息内容。
而写出所有中间哈希值,就类似于思维链如何让模型在时间上展开推理。
果然,Magic团队的成果已经获得了大佬投资者的青睐。
现在,团队已经获得4.65亿美元融资了。Eric Schmidt、Jane Street、红杉资本和Atlassian等,就已经投资了3.2亿美元。
计算和内存比注意力机制少1000多倍
LTM-2-Mini强在哪里?
Magic所采用的LTM(长期记忆)机制所需的计算和内存,比Llama 3.1 405B的注意力机制少了1000多倍,这个对比太鲜明了。
Llama 3.1的每个用户,都需要638个H100来存储1亿token的KV缓存,而LTM只需要其中的一小部分。
此前流行的「大海捞针」,存在很多弱点,SSM、RNN和RAG都是利用了它们。
因此,这次团队为了规避「大海捞针」的弱点,专门创建了全新的评估方法HashHop——
1. 不可压缩
2. 多跳
3. 无语义提示
4. 无新近性偏差
在解决了上下文问题之后,现在就可以专注于无限推理时间的计算能力了!
这,很可能就是构建AGI所需的下一个突破,甚至,是最后一个突破。
只要花费100美元,你就可以在10分钟内完成一个任务,还能获得一个可靠的具有完整功能的pull request。
简直太诱人了!
而Magic,就致力于让这个目标成真。
现在,这个拥有8000个H100的23人团队,还有一个更大的目标:共同设计长上下文、推理时间的计算能力和端到端强化学习,实现编码和研究的全自动化。
网友:show me the paper
网友感慨:所以,团队是同时构建了SSM、RNN或Transformer?
知名AI博主Chubby感慨道:我的天,它成功勾起了我的好奇心——基准测试结果到底如何。
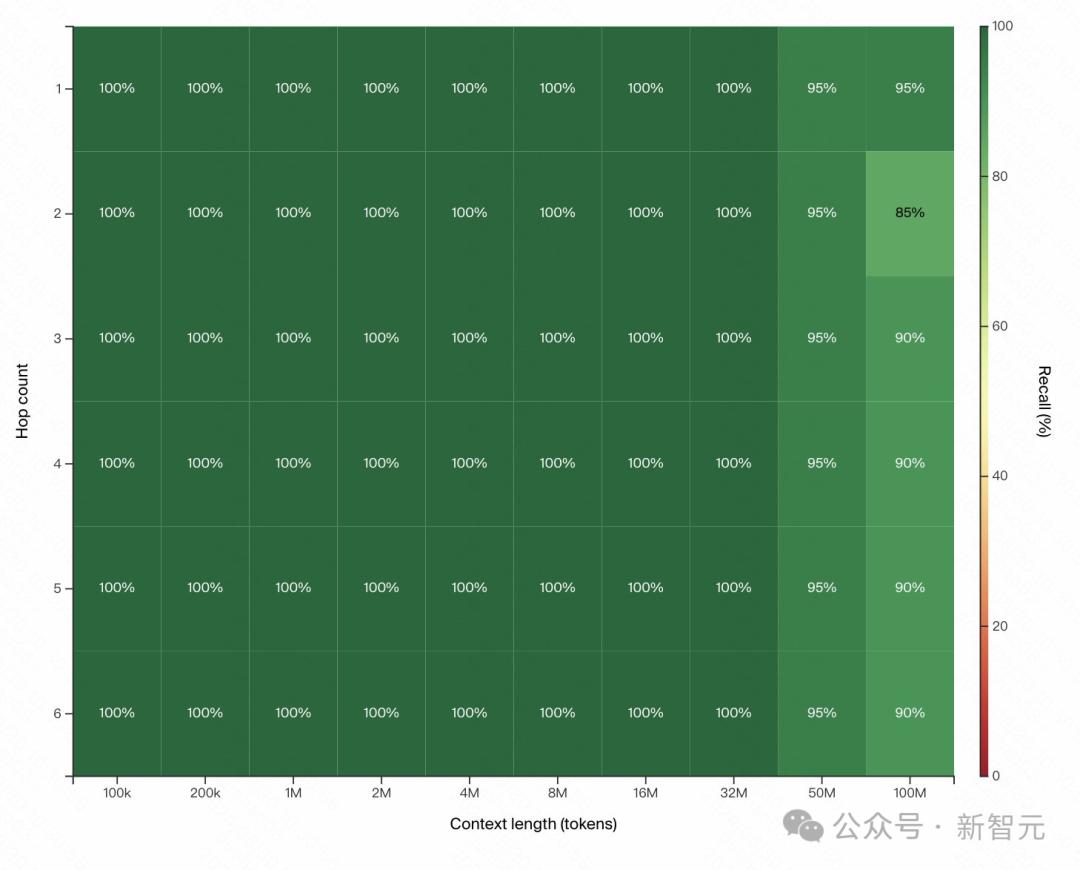
3200万token,100%召回率,这太疯狂了!
不过,理解1000行代码的任务,模型真能做到吗?

SOUND VENTURES的投资人更是表示,Magic团队在上下文上的取得突破,可以说是改变了游戏的规则。

不过,Reddit网友普遍并不买账。
比如,为什么专挑Llama 3.1 405B做对比呢?如果模型比405B小100倍,那比它便宜1000倍,也是有可能的。
而且,团队也没有给出模型或论文之类更硬核的东西,甚至没有说明需要多少内存。
说了这么多,论文在哪里?
另外还有人质疑:即使是在大海捞针中准确率达到100%的模型,有效上下文长度也往往超不过32k,因此仅仅增加理论窗口,是没有意义的。
1亿token超超超长上下文
关于研究过程的具体细节,团队是这样解释的。
目前,AI 模型有两种学习方式:训练和推理时的上下文中的学习。
由于上下文相对较短,训练一直占据主导地位。但超长上下文,可能会改变这一点。
而LTM(长期记忆)模型并不依赖模糊记忆,而是在推理时被训练处理多达1亿token的上下文。
就如上文所说,如果模型能够在上下文中包含所有代码、文档和库,包括那些不在公共互联网上的代码,代码合成的表现,提升将是惊人的。
上下文窗口评估
团队首先就上来强调说,当前的长上下文评估并不理想。
流行的「大海捞针」评估是在长上下文窗口(「海」)放置一个随机事实(「针」),并让模型检索该事实。
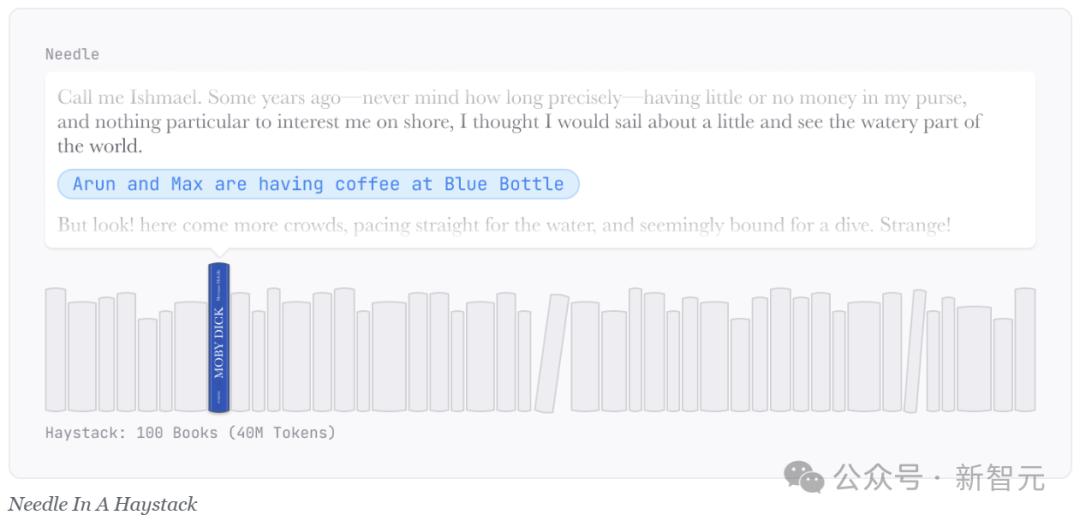
然而,在一本关于鲸鱼的小说中,「在Blue Bottle喝咖啡的Arun和Max」显得格外突出。
通过学习识别这种「针」的不寻常性质,模型可以忽略「海」中其他本来相关的信息,从而将所需的存储容量减少到低于处理真实任务时的水平。
并且,模型只需要关注上下文中一个微小且语义上可识别的部分即可。于是,像RAG这样的方法也能获得成功。
Mamba和H3的归纳头基准测试,使这一点变得更加容易。
在训练中,它们使用了一个特殊的token,来明确标记针的开始,使评估的存储和检索难度降低到O(1)。
这就好比,在开始学习之前就知道考试中会出现哪个问题一样。
正是这些微妙的缺陷,削弱了当前长上下文评估的有效性,使传统的递归神经网络(RNN)和状态空间模型(SSM)能够取得好成绩,尽管它们从根本上限制了O(1)大小的状态向量。
为了消除这些隐性和显性语义提示,Magic设计了一种全新的方法——HashHop。
哈希是随机的,也是不可压缩的。因此,这将要求模型能够随时从给定上下文大小的最大可能信息内容中,进行存储和检索。
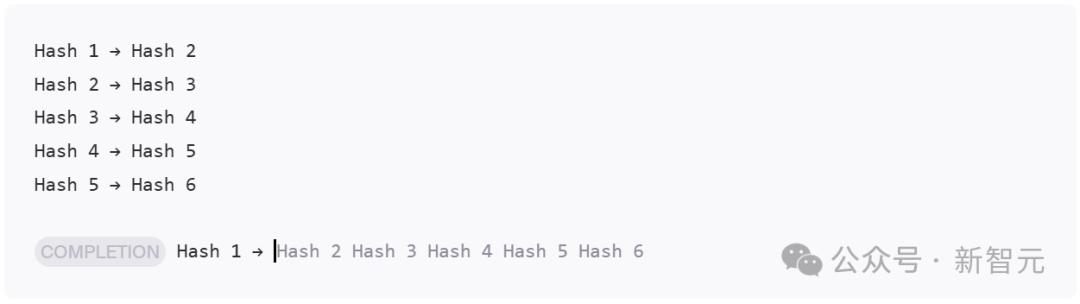
具体而言,先用哈希对来提示经过训练的模型:

然后,要求它完成一个随机选择的哈希对的值:

这用于衡量单步归纳头的出现,但实际应用通常需要多步,比如在代码库中进行变量赋值或库导入的情况。
为此,团队要求模型完成一串哈希链:
为了确保顺序和位置的无关性,在提示词中打乱哈希对的顺序:
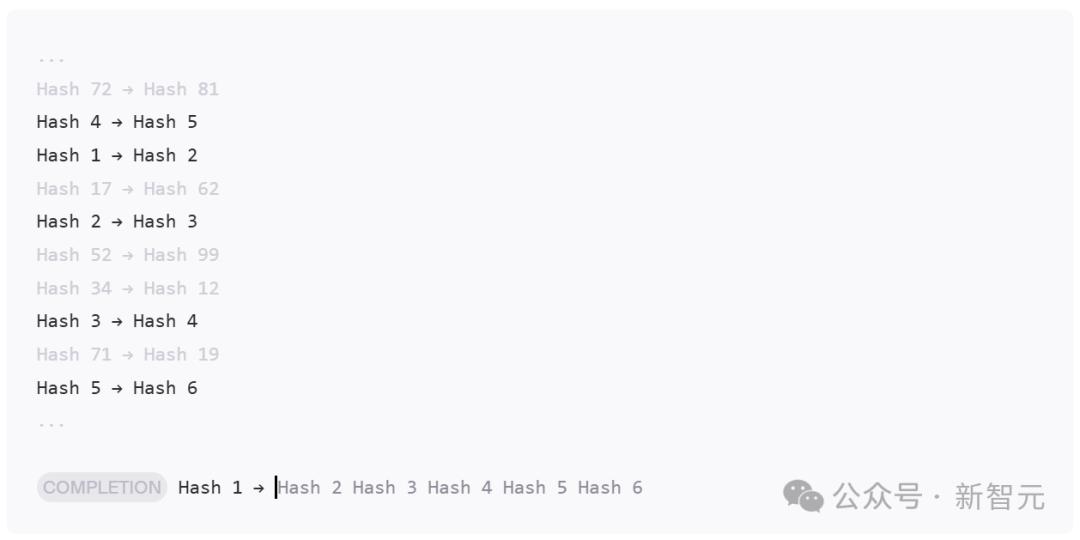
写出所有中间哈希值类似于思维链,让模型可以在时间上展开推理。
此外,团队还提出了一种更具挑战性的版本,其中模型跳过步骤,例如直接从哈希1跳到哈希6:

这要求模型架构能够在潜空间中一次性关注并跨越整个上下文的多个点。
效果如何?
接下来就让我们看看Magic提出的第一个拥有1亿token上下文的模型——LTM-2-mini。
就如上文所说,对于每个解码的token,LTM-2-mini的序列维度算法在1亿token上下文窗口中比Llama 3.1 405B的注意力机制便宜大约1000倍。
而内存需求的对比,就更加明显了——
运行具有1亿token上下文的Llama 3.1 405B,仅仅是存储单个1亿token的KV缓存,就需要每个用户638个H100。
相比之下,LTM的每个用户在相同上下文中,只需要使用单个H100的HBM的一小部分。
在哈希值上进行思维链训练后,LTM架构得到了以下结果:
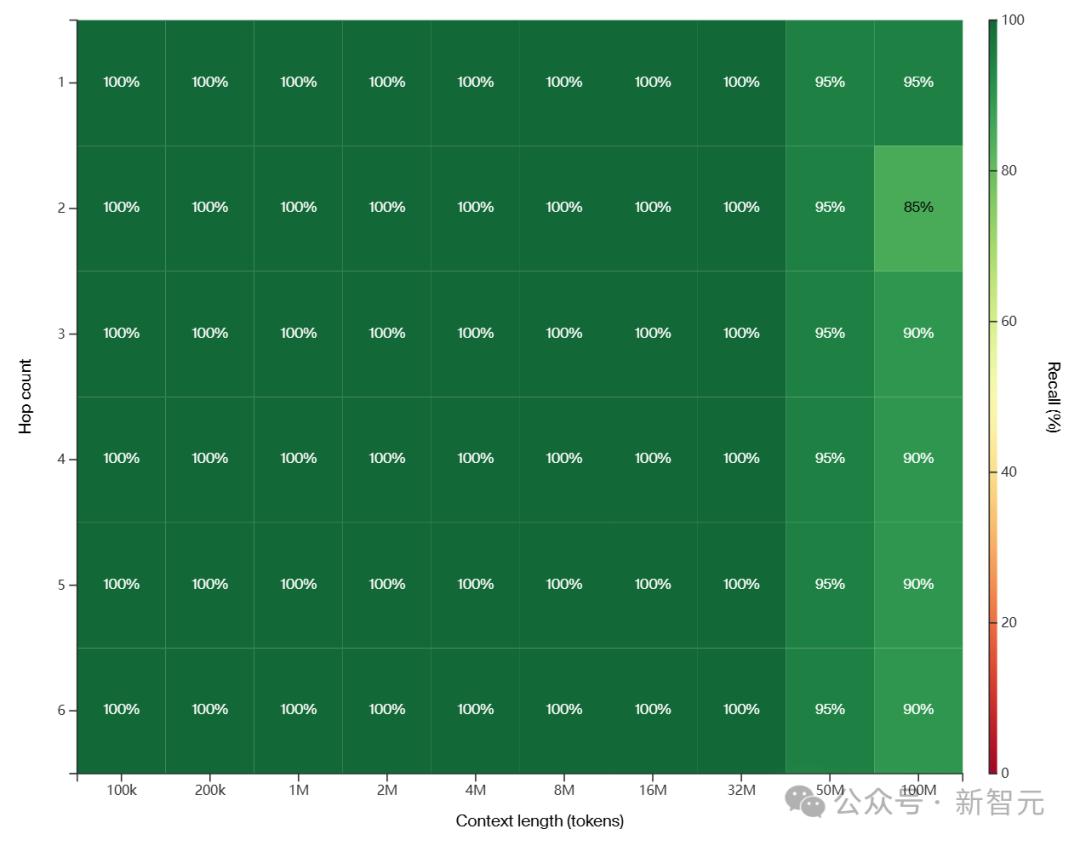
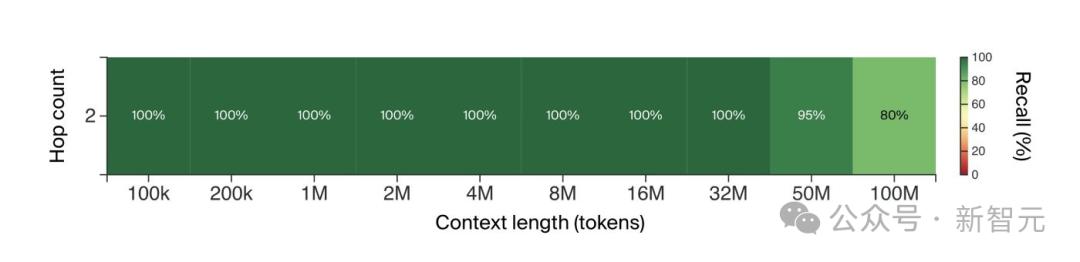
在特定模型的超参数选择中,当尝试3跳或更多跳而不使用思维链时,性能会下降。
但尝试2跳(哈希1→哈希3)时,即便没有思维链也可以得到很好的结果。
这意味着,模型能够构建比单归纳头更复杂的回路:

最后,团队还使用超长上下文机制在文本到差异的数据上训练了一个原型模型。
它比SOTA模型小了几个数量级,因此代码合成能力还不够好,但偶尔也会产生合理的输出:
- 上下文GUI框架
虽然对于使用 React 等知名框架的先进模型来说,生成计算器是一项简单的任务,但使用自定义的上下文框架更具挑战性。
其中,模型的提示只有代码库和聊天记录(没有打开的文件、编辑历史或其他指示)。
这里,LTM模型成功地使用自定义的上下文GUI框架创建了一个计算器,展示了实时学习的能力。
- 简单的UI修改
对于这个问题的描述,实际上要在比现实场景中更加具体,并且这项功能在许多web应用程序中很常见。
尽管如此,一个比当今SOTA模型小几个数量级的模型,仍然能够在无人协助的情况下编辑复杂的代码库。
可以看到,LTM模型能够在没有人工干预的情况下,为开源仓库Documenso实现一个密码强度计。
与Google Cloud合作
目前Magic正在Google Cloud上构建两台超级计算机,计划于明年上线:
- Magic-G4,由NVIDIA H100 Tensor Core GPU提供支持
- Magic-G5,由NVIDIA GB200 NVL72提供支持
据称,后者能够随着时间的推移扩展到数万台Blackwell GPU,并且这些集群将能够实现160 exaflops(每秒一百亿亿次操作)。
创立2年,总融资4.65亿美元
扒了一下Magic团队的背景后,我们发现这又是一段熟悉的天才少年故事。
Magic这家公司,是Eric Steinberger和Sebastian De Ro在2022年创立的。

其实,早在上高中时,联创兼CEO Steinberger就感受到了AI的「召唤」。
那时,他就会和朋友们把学校的计算机连接起来进行机器学习算法训练。
而这段经历,也促使Steinberger进入剑桥大学学习计算机科学。

不过,他在一年后选择辍学,并去了Meta担任AI研究员。
另一位联创De Ro,来自德国业务流程管理公司FireStart。在那里,他的职位一路晋升至CTO。
二人的相识,是在Steinberger创立的环境志愿者组织ClimateScience.org中。
Magic的团队规模很小——大约有二十几个人,并且没有收入。
但现在,公司已经不可同日而语了。
Magic的野心:AGI
随着AI辅助编码工具不断改进,开发者的热情可谓是只增不减。
GitHub最新的调查显示,大部分开发者都已以某种形式采用了AI工具。同时,微软也在4月份报告称,Copilot已经拥有超过130万付费用户和超过50,000家企业客户。
根据Polaris Research的估计,这个市场到2032年可能将价值271.7亿美元,而投资者对此也十分看好。
在发布新模型的同一天,Magic表示自己已经完成了3.2亿美元的融资轮。包括前Google CEO Eric Schmidt以及Alphabet的CapitalG、Atlassian、Elad Gil、Jane Street、Nat Friedman和Daniel Gross、红杉等。
随着总融资来到4.65亿美元,Magic也正式跻身「资金充足」的AI编码初创公司之列,其中包括Codeium、Cognition、Poolside、Anysphere和Augment。(有趣的是,Schmidt也投资了Augment。)
当然,Magic的雄心不仅仅是自动化常规软件开发任务。
在官网上,他们还提到了AGI。
为此,Magic聘请了前OpenAI超级计算团队负责人Ben Chess,并计划扩展其网络安全、工程、研究和系统工程团队。

按照他们的设想,花100美元在10分钟内完成一个任务,获得可靠的具有完整功能的pull request,这已经可以算是AGI的雏形了。
参考资料:
https://magic.dev/blog/100m-token-context-windows
https://techcrunch.com/2024/08/29/generative-ai-coding-startup-magic-lands-320m-investment-from-eric-schmidt-atlassian-and-others/



